Notes & Conclusion
The ideal computer can handle arbitrarily diverse and complicated tasks in parallel. In reality though, there are always trade-offs to be made which is why we develop different architectures most commonly the CPU and the Graphics Processing Unit (GPU). CPUs are great at handling various diverse complicated tasks one by one. GPUs are great at handling the many of the same simple tasks in parallel. But there is much more to modern designs than what I have talked about up until and I want to create a little overview.
Modern CPUs
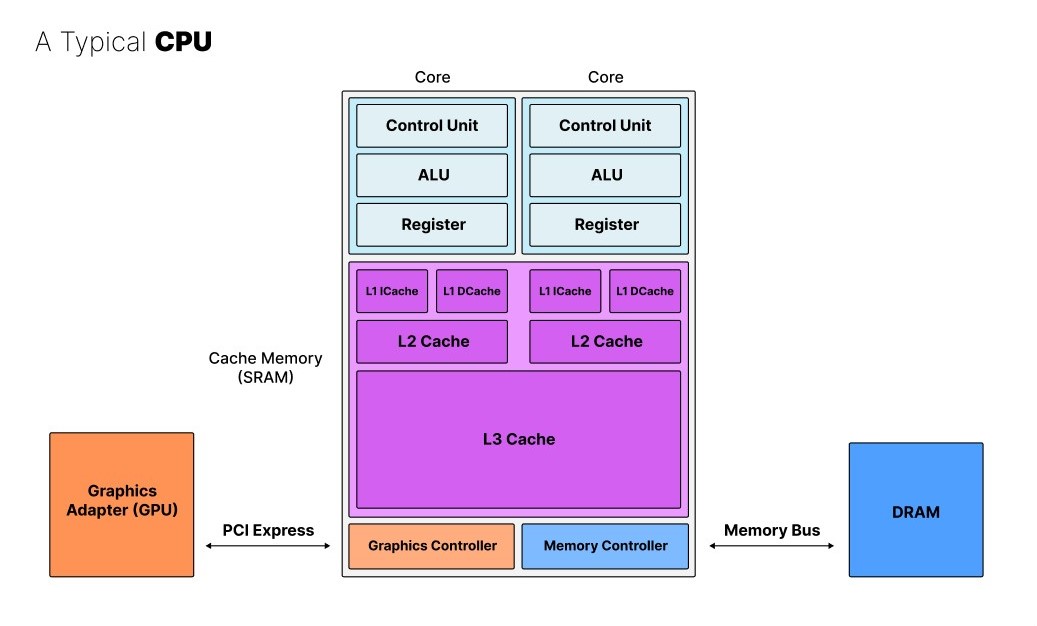
To summarize this video, below, you can see a schematic overview of a typical CPU with multiple processing cores consisting of a control unit, ALU, and register coupled to various levels of cache memory (SRAM), and including a graphics controller which is typically connected to a GPU and a memory controller which in turn is connected to DRAM memory via a memory bus.
 |
|---|
| Schematic overview of a typical modern CPU. |
The different caches operate at varying speeds to distribute data among the cores efficiently. To further optimize the data exchange between the cores and the memory, the L1 cache is split into an instruction cache (ICache) and data cache (DCache). The ICache only writes and hence tells the core which operations to execute while the DCache only writes and reads data to and from the core.
If we compare this with the Hack computer architecture, its minimalism becomes clear. Modern CPUs have much more advanced capabilities. To summarize:
- Branching: Modern CPUs have advanced branching capabilities, which allow them to make decisions and execute different code paths based on various conditions. This is a crucial feature that allows CPUs to handle complex, diverse tasks.
- Multiple Cores: Modern CPUs typically have multiple processing cores, allowing them to execute multiple tasks or threads concurrently, improving overall performance. This became crucial in recent decades as Moore's Law started failing. And it goes much further than the original von-Neumann architecture.
- Hierarchical and More Optimized Cache: As mentioned, modern CPUs have a hierarchical cache system (L1, L2, L3) with specialized instruction and data caches (the so-called Harvard architecture, again, different from the von-Neumann architecture), which helps to efficiently manage and distribute data between the cores and main memory.
- Graphics Controller: Many modern CPUs integrate a graphics controller, which offloads some graphics processing tasks from the main CPU cores, improving overall system performance.
- Larger Instruction Set and More Complex ALU/Control Unit: Modern CPUs have a much larger and more complex instruction set, as well as more advanced Arithmetic Logic Units (ALUs) and Control Units, allowing them to handle a wider range of operations and tasks.
Modern GPUs
Modern graphics are extremely data intensive (hence the PCI Express for greater bandwidth) and demand for parallel compute (hence vast amounts of cores a.k.a. "shader cores"). While there are many cores they all have comparatively simple instructions though. It follows the "Single Instruction, Multiple Data" (SIMD) paradigm. This is possible because there is a much more clear and repetitive pipeline for GPUs. After all, they were originally and are still primarily meant for graphics acceleration. Below, you can see an illustration of the graphics rendering pipeline (as summarized by this video).
 |
|---|
| Schematic overview of a typical GPU's graphics rendering pipeline. |
Note also, that GPUs have no need for registers.
GPUs are quite general these days but they are still primarily optimized to handle graphics. So while they can also run parallel physics or neural networks, a dedicated physics processing unit or dedicated AI accelerators are still outperforming GPUs by a lot. The reason we do not see much of this yet is the ecosystem NVIDIA has built around their graphics cards and monopolizes. Indeed, NVIDIA introduced a dedicated core to solve the computationally heavy task of ray-tracing a few years ago. It will take time to build the software, workflows, hardware, and various integrations etc. for AI accelerators to take over. It will take even longer for this to happen for physics processors given that there is no clearly communicated demand for it on the market right now.
Parallelism: SISD to MIMD
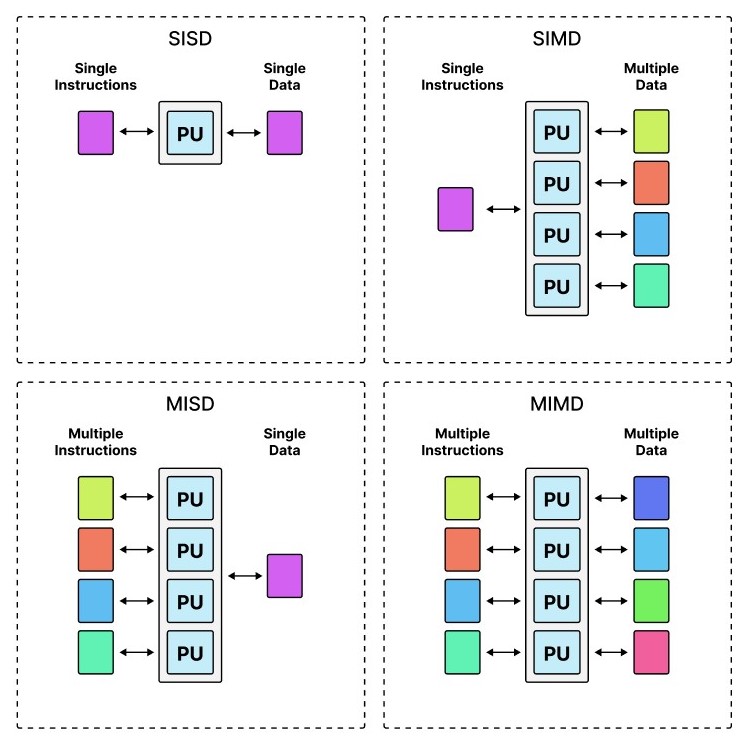
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously rather than "Single Instruction, Single Data" (SISD) as in the Hack computer we've built. Below is an illustration of the general idea layed out originally in Flynn's Taxonomy:
 |
|---|
| Flynn's Taxonomy of (parallel) processing with single or multiple data or instructions. |
GPUs are SIMD. And where the original computer and CPU was clearly SISD, modern CPUs, especially those used for supercomputers, are now typically MIMD, so that various different applications with different data can run in parallel. Yet, the complexity of such an architecture only allows for a relatively low number of cores compared to SIMD. Hence, ultra-parellilsm is only really feasable with SIMD.